正则表达式
正则表达式
Python-re 库
re.match
re.match(pattern, string, flags=0)
尝试从字符串的起始位置匹配一个模式。匹配成功 re.match 方法返回一个匹配的对象。没有匹配成功的,re.search()返回 None。
group()用来提出分组截获的字符串,()用来分组,group() 同 group(0)就是匹配正则表达式整体结果,group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分。
2
3
4
>> result = re.match("itcast","itcast.cn")
>> result.group()
'itcast'
| arg | 说明 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 1. re.I 忽略大小写 2. re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境 3. re.M 多行模式 4. re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符) 5. re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库 6. re.X 为了增加可读性,忽略空格和 # 后面的注释 |
re.compile
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
2
3
4
result = prog.match(string)
# 等价于
result = re.match(pattern, string)
- group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
- start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
- end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
- span([group]) 方法返回 (start(group), end(group))
re.search
re.search 扫描整个字符串并返回第一个成功的匹配,如果没有匹配,就返回一个 None。
re.match 与 re.search 的区别:re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None;而 re.search 匹配整个字符串,直到找到一个匹配
2
3
4
5
ret = re.search(r"\d+", "阅读次数为9999")
print(ret.group())
9999
re.findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。注意: match 和 search 是匹配一次 findall 匹配所有。
举例:
2
3
4
5
ret = re.findall(r"\d+", "python = 9999, c = 7890, c++ = 12345")
print(ret)
['9999', '7890', '12345']
re.finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
2
3
4
5
6
7
8
9
10
it = re.finditer(r"\d+", "12a32bc43jf3")
for match in it:
print(match.group())
>>>
12
32
43
3
re.sub
sub 是 substitute 的所写,表示替换,将匹配到的数据进⾏替换。
2
3
4
5
ret = re.sub(r"\d+", '998', "python = 997")
print(ret)
python = 998
re.sub(pattern, repl, string, count=0, flags=0)
| 参数 | 描述 |
|---|---|
| pattern | 必选,表示正则中的模式字符串 |
| repl | 必选,就是 replacement,要替换的字符串,也可为一个函数 |
| string | 必选,被替换的那个 string 字符串 |
| count | 可选参数,count 是要替换的最大次数,必须是非负整数。如果省略这个参数或设为 0,所有的匹配都会被替换 |
| flag | 可选参数,标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
re.subn
行为与
sub()相同,但是返回一个元组(字符串, 替换次数)。
2
3
4
5
6
7
8
9
10
11
pattern = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!'
print(re.subn(pattern, r'\2 \1', s))
def func(m):
return m.group(1).title() + ' ' + m.group(2).title()
print(re.subn(pattern, func, s))
>>>
('say i, world hello!', 2)
('I Say, Hello World!', 2)
re.subn(pattern, repl, string[, count])
return: (sub(repl, string[, count]), 替换次数)
re.split
根据匹配进⾏切割字符串,并返回⼀个列表。
2
3
4
5
ret = re.split(r":| ","info:xiaoZhang 33 shandong")
print(ret)
['info', 'xiaoZhang', '33', 'shandong']
re.split(pattern, string, maxsplit=0, flags=0)
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| maxsplit | 分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数 |
r’’
字符串前⾯加上 r 表示原⽣字符串
1 | import re |
正则表达式基础知识
普通字符
| 字符 | 描述 |
|---|---|
| [ABC] | 匹配 […] 中的所有字符,例如 [aeiou] 匹配字符串 “google runoob taobao” 中所有的 e o u a 字母。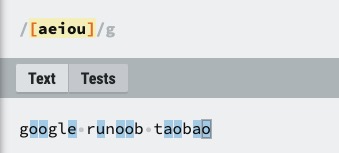 |
| ABC | 匹配除了 […] 中字符的所有字符,例如 aeiou 匹配字符串 “google runoob taobao” 中除了 e o u a 字母的所有字母。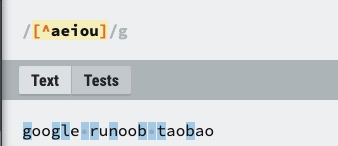 |
| [A-Z] | [A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母。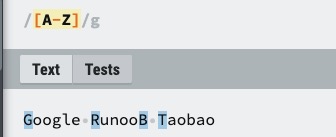 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符,相等于 \n\r。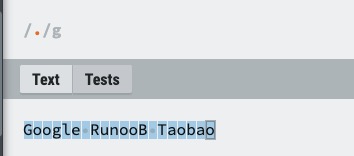 |
| [\s\S] | 匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。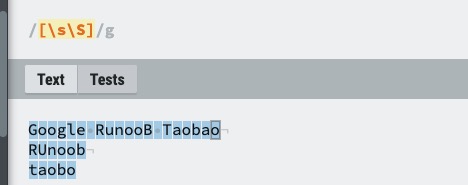 |
| \w | 匹配字母、数字、下划线。等价于 [A-Za-z0-9_]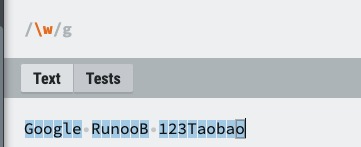 |
| \w | 匹配⾮单词字符 |
| \d | 匹配数字,即 0-9 |
| \D | 匹配⾮数字,即不是数字 |
非打印字符
| 字符 | 描述 |
|---|---|
| \cx | 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 |
| \S | 匹配任何非空白字符。等价于 \f\n\r\t\v。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
特殊字符
| 特别字符 | 描述 | |||
|---|---|---|---|---|
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。要匹配 $ 字符本身,请使用 \$。 |
|||
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 ( 和 )。 | |||
| * | 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。 |
|||
| + | 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用\+。 |
|||
| . | 匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用\. 。 |
|||
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用\[。 |
|||
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
|||
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n’ 匹配字符 ‘n’。’\n’ 匹配换行符。序列 ‘\\‘ 匹配 “\“,而 ‘\(‘ 则匹配 “(“。 |
|||
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用\^。 |
|||
| { | 标记限定符表达式的开始。要匹配 {,请使用\{。 |
|||
| \ | 指明两项之间的一个选择。要匹配 \ | ,请使用` \ | `。 |
限定符
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于 {0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,zo+ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,do(es)? 可以匹配 “do” 、 “does”、 “doxy” 中的 “do” 和 “does”。? 等价于 {0,1}。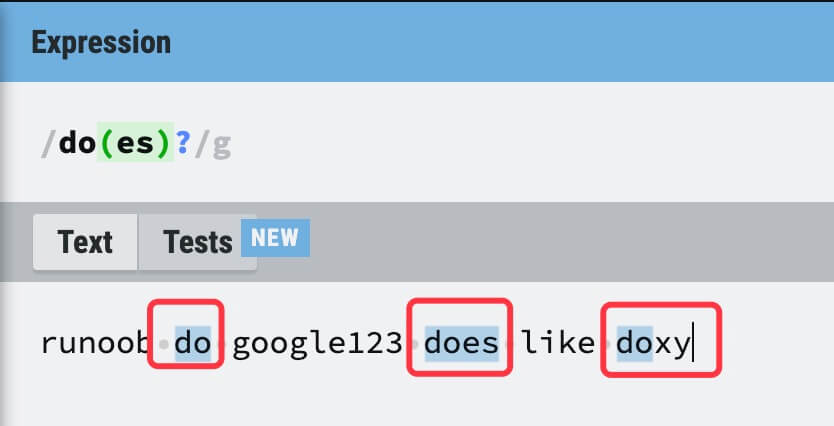 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,o{2} 不能匹配 “Bob” 中的 o,但是能匹配 “food” 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配 n 次。例如,o{2,} 不能匹配 “Bob” 中的 o,但能匹配 “foooood” 中的所有 o。o{1,} 等价于 o+。o{0,} 则等价于 o*。 |
| {n,m} | m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,o{1,3} 将匹配 “fooooood” 中的前三个 o。o{0,1} 等价于 o?。请注意在逗号和两个数之间不能有空格。 |
定位符
| 字符 | 描述 |
|---|---|
| \^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,\^ 还会与 \n 或 \r 之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 |
| \b | 匹配一个单词边界,即字与空格间的位置。 |
| \B | 非单词边界匹配。 |
贪婪与非贪婪
属于贪婪模式的量词,也叫做匹配优先量词,包括:
“{m,n}”、“{m,}”、“?”、“*”和“+”。
在一些使用 NFA 引擎的语言中,在匹配优先量词后加上“?”,即变成属于非贪婪模式的量词,也叫做忽略优先量词,包括:
“{m,n}?”、“{m,}?”、“??”、“*?”和“+?”。
 wechat
wechat- alipay



